使用 Python 美化文本,使中文与英文,数字,标点之间添加空格
bolg 也写了一段时间了,可是最近发现,好像排版有点问题,之前一直没注意,因为是码农缘故吧, blog 中会有中文,英文,数字等,可是很多时候没注意,就直接中英文挨着写了,中间没有加空格,导致很多地方不美观。
就如下图所示
 很多英文都是紧挨着中文的,个人觉得中英文直接有空格隔开,看起来更舒服。如下图所示。
很多英文都是紧挨着中文的,个人觉得中英文直接有空格隔开,看起来更舒服。如下图所示。

作为一个码农,要是自己一个一个的修改的话,就会太 low 啊了。 因为之前也学了一点 Python ,就想着用 Python 写个脚本来来处理。
思路:
- 遍历整个 blog 文章目录,找到每一个文件
- 一行一行的读取文件,
- 区分中文和英文,在英文前面后面添加上空格
- 然后把整理好的一行再写入该文件中。
忙了一晚上吧,大概弄出来了,中间遇到一些坑吧,就不在记录,只把源码贴上去
# coding=utf-8
import os
import re
def is_Chinese(word):
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
def is_al_num(word):
# 因为定义的一些变量或者方法可能带有下划线
# 还有一些分割的时候,把两个单次分割到了一块,所以带有空格,还有一些带(),所以先把这些去掉,再进行判断
word = word.replace("_", "").replace(" ", "").replace("()", "").encode('UTF-8')
if word.isalpha():
return True
if word.isdigit():
return True
if word.isalnum():
return True
return False
def beautifyText(text, pattern , isloop):
"""
美化文案,中英文,英文与数字,中文与数字直接都添加空格
:param text: 要美化的原始文案
:param pattern: 替换规则
:param isloop: 如果不符合规则的,是否根据新的规则继续美化
"""
res = re.compile(pattern) # [\u4e00-\u9fa5]中文范围
p1 = res.split(text)
result = ""
for index in range(len(p1)):
str = p1[index]
if "\n" == str:
result += str
continue
# if len(str.strip()) == 0:
# # 空白字符直接返回
# continue
if is_Chinese(str):
# 说明是中文
result += str;
elif is_al_num(str):
# 是纯英文,或者纯数字,或者英文和数字组合,则前后加上空格
if isloop and index == 0:
# 第一行的首个是数字或者英文,直接在后面添加空格,前面不需要
result += (str.strip() + " ");
else:
result += (" " + str.strip() + " ");
else:
if isloop:
# 使用新的规则,继续美化,这里主要是根据一些中文,英文常用符号
result += beautifyText(str, r"([。,?!,!]+)", False)
else:
result += str
return result
def beatifyFile(file):
f1 = open(file, 'r+')
infos = f1.readlines()
print("len: " + str(len(infos)))
f1.seek(0, 0)
for line in infos:
new_str = beautifyText(line, r"([\u4e00-\u9fff])", True)
line = line.replace(line, new_str)
f1.write(line)
f1.close()
def test(s):
print("原始:" + s)
text = beautifyText(s, r"([\u4e00-\u9fff])", True)
print("转换:" + text)
def DirAll(pathName):
if os.path.exists(pathName):
fileList = os.listdir(pathName)
for f in fileList:
f = os.path.join(pathName, f)
if os.path.isdir(f):
DirAll(f)
else:
baseName = os.path.basename(f)
if (baseName.startswith(".")):
continue
print(f)
beatifyFile(f)
if __name__ == '__main__':
rootdir = '/Users/hoyouly/llll/hoyouly.github.io/_posts'
DirAll(rootdir)
# beatifyFile("./article-template.md")
test("景 高 Disruptr , Linux 环形缓存,");
把 rootdir 改成自己要修改的文件夹就行了。
下面是一些修改好对比效果

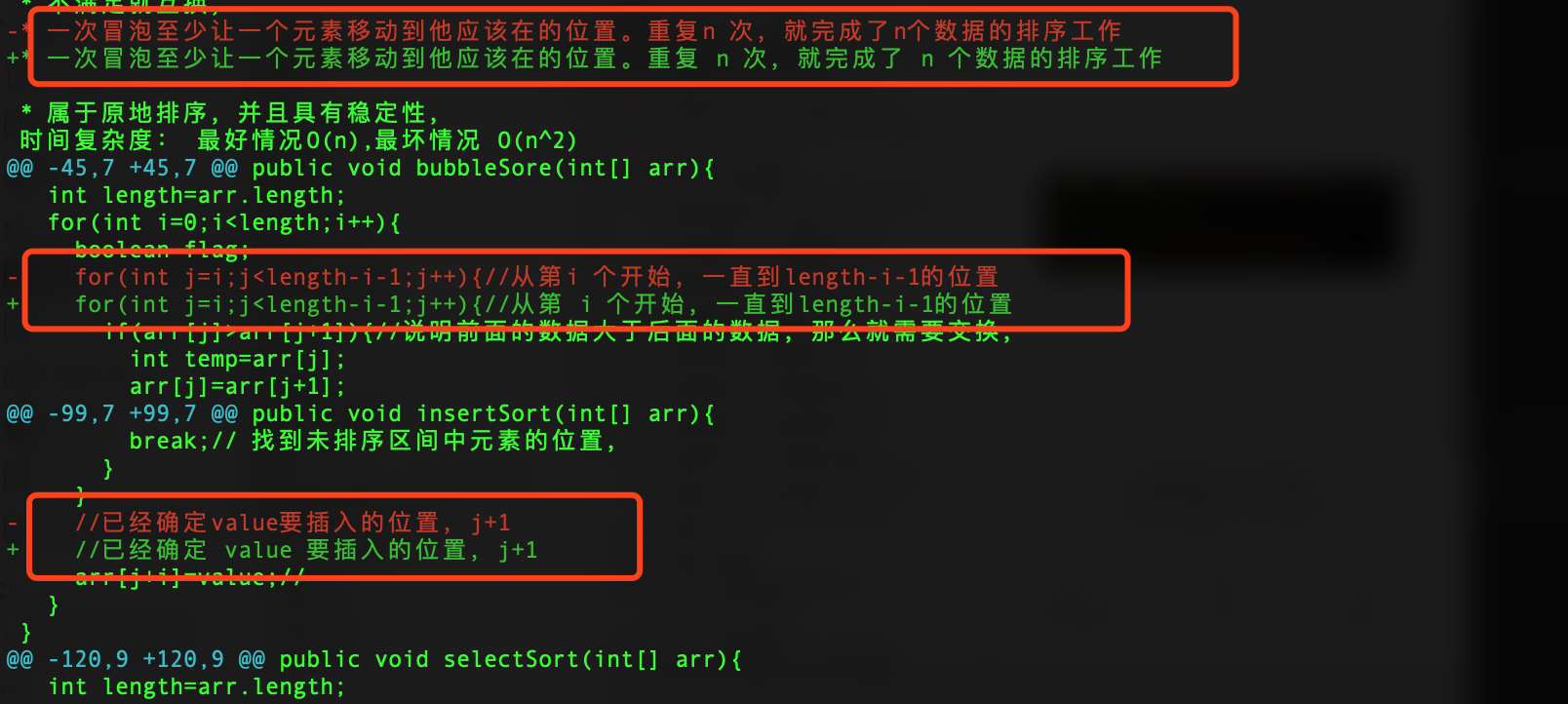
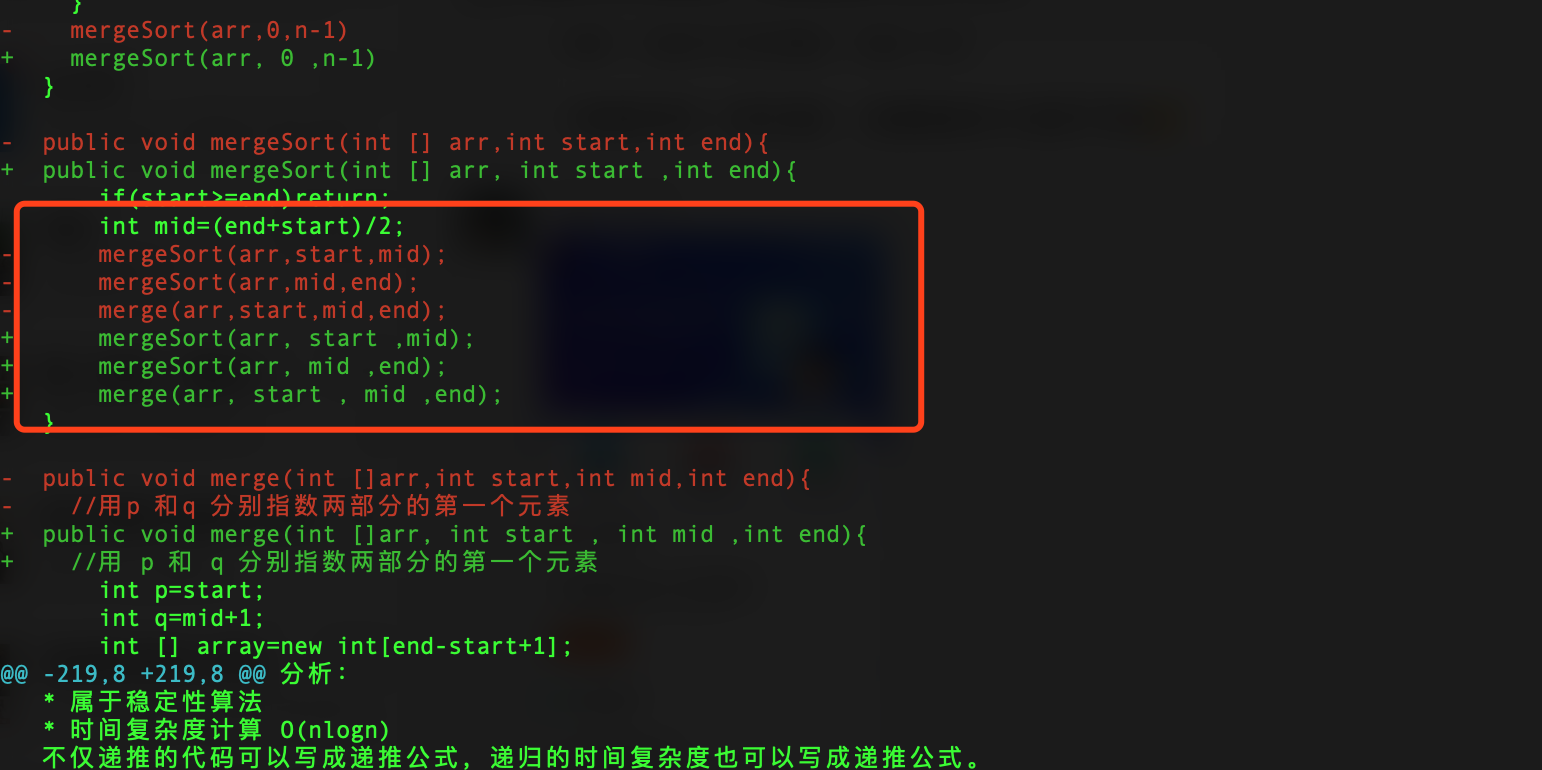
英文前后都加了空格,连代码中都处理了。
虽然可能还有些没处理好。但是已经比之前好看多了。
搬运地址:
既已览卷至此,何不品评一二: